Nach seinem Studium der Physik und anschließender Promotion Wechsel in die IT-Branche. Seit mehr als 20 Jahren als Entwickler, Berater und Projektleiter vorwiegend im Bereich Java und JavaScript unterwegs. Parallel dazu in der Entwicklung und Durchführung von hochwertigen Seminaren für die Integrata im Einsatz.
Obwohl der Begriff NoSQL schon im Jahre 1998 (https://de.wikipedia.org/wiki/NoSQL) geprägt wurde und mittlerweile im allgemeinen IT-Sprachgebrauch etabliert ist, ist eine genaue Definition auch heute noch nicht eindeutig etabliert.
In dieser Reihe möchte ich das Versionsverwaltungssystem Git vorstellen, das auch für Java-Seminare der Integrata benutzt wird, um den Teilnehmern eine komfortable Arbeitsumgebung zu definieren. Weiterhin werden die Musterbeispiele für verschiedene Seminare über öffentliche Git-Server bereitgestellt.
Dieser erste Teil liefert eine Kurzeinführung in das elementare Arbeiten mit Git.
Teil 2 stellt das Eclipse-PlugIn für Git vor, da Eclipse die Standard-Entwicklungsumgebung bei der Integrata ist.
Teil 3 schließlich zeigt, wie Git in Java-Seminaren benutzt werden kann.
Eine Kurzeinführung in Git
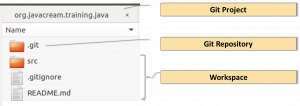
Ein Versionsverwaltungssystem ermöglicht es, verschiedene Stände eines Dateibestands eindeutig und reproduzierbar abzulegen. Solche Systeme sind innerhalb eines Software-Projekts unverzichtbar, um Quellcodes und Konfigurationsdateien abzulegen. Git ist ein so genanntes Verteiltes Source Code Management System. Das bedeutet, dass auch ohne Server-Anbindung auf jedem Rechner mit Git-Installation ein vollständiges Versionsverwaltungssystem, ein so genanntes Git-Repository, zur Verfügung steht. Ein Repository besteht aus einer internen Dateiablage (das Verzeichnis .git), das enthaltende Verzeichnis ist der Arbeitsbereich des Git-Projekts.
“Vollständig” bedeutet, dass der Anwender unter anderem die folgenden Befehle benutzen kann, die typisch für das Arbeiten mit einem Versionsverwaltungssystem sind:
commit
Mehrere Änderungen an einem Bestand werden mit einer Beschreibung versehen und im Versionsverwaltungssystem abgelegt. Dabei schreitet der aktive Branch mit jedem commit einen Schritt voran.
Bei Git müssen Dateien mit Hilfe des Befehls add erst einmal für eine Änderung vorgemerkt werden.
branch
Erzeugt einen neuen Branch, auf dem dann unabhängig weiterentwickelt werden kann. Branches können beliebig benannt werden und in beliebiger Anzahl existieren.
checkout <branch-name>
Die Dateien eines Branches werden in den Arbeitsbereich kopiert.
merge <branch-to-merge>
Änderungen eines Branches werden mit einem anderen Branch zusammengeführt. Dies kann natürlich zu Konflikten führen, diehändisch bereinigt werden müssen.
status
Zeigt den aktuellen Status des Repositories an, also beispielsweise geänderte oder neu hinzugefügte Dateien.
Git Server
Die Benutzung eines gemeinsamen Servers ist auch bei Git sinnvoll möglich. Im Internet sind Git-Server nach Anmeldung frei verfügbar, in denen dann beliebig viele Repositories angelegt werden können. Bekannt sind hier GitHub und GitLab.
Ist auf einem Git-Server ein Repository eingerichtet, wird kann dieses bei vorhandener Internet-Verbindung als lokales Repository “gecloned” werden.
Zur Verwendung eines Remote Repositories werden zusätzliche Befehle benötigt:
clone <directory or url>
Das entfernte Repository wird komplett in das aktuelle lokale Verzeichnis übertragen.
pull
Stehen auf dem entfernten Repository neue Versionen zur Verfügung, so werden diese in das lokale Verzeichnis übernommen.
Hierbei wird effektiv der lokal vorhandene Branch mit dem korrespondierenden entfernten Branch gemerged. Dabei können natürlich wiederum Konflikte auftreten, die im lokalen Repository gelöst werden müssen.
push
Lokale Änderungen werden in das entfernte Repository übertragen. Das entfernte Repository wird aber diese Änderungen nur akzeptieren können, wenn keine Konflikte vorhanden sind.
So müssen im normalen Workflow in Git vor einempusherst einmal der potenziell geänderte Stand gepulled werden. Dann werden die Stände lokal konsolidiert und anschließend erst hochgepushed.
Ein Beispiel
Auf GitLab.com steht ein simples Projekt mit einer einzigen Datei namens README.md zur Verfügung. Dieses wird in auf einem lokalen Rechner gecloned
Mit der Programmiersprache Swift hat Apple ein modernes Werkzeug für die Anwendungsentwicklung für Mac und iOS bereit gestellt. Diese Sprache löst das von vielen Entwicklern als etwas gewöhnungsbedürftig und sperrig betrachtete Objective C ab. Mit der aktuellen Version 3 steht eine erste vollständige und unabhängige Implementierung zur Verfügung. Die anstehende Version 4 wird weitere Features einführen, jedoch keine Änderungen an der Core-Sprache mehr vornehmen.
Swift wurde von Apple als Open Source-Initiative freigegeben und steht damit auch für andere Plattformen zur Verfügung, z.B. für Ubuntu. Eine durchaus beachtenswerte Abkehr von der bisherigen Abschottung der Apple-Produkte. Allerdings gilt dies natürlich nur für den Kern der Sprache, die App-Programmierung muss aus Lizenz-Gründen weiterhin unter Apple Hardware und Betriebssystem erfolgen. Diese Einschränkung ist für diesen Artikel allerdings nicht relevant, da ich mich hier bewusst auf den Vergleich der Programmiersprachen konzentrieren möchte; für einen (durchaus interessanten!) Vergleich von Google Android und Apple Swift gibt es andere Artikel.
Swift vereinigt etablierte Konzepte aus Sprachen wie Java, C#, JavaScript und natürlich auch Objective C und ergänzt diese durch eigene Ideen. Damit finden Programmierer einesteils recht viel Bekanntes, aber eben auch unerwartete und damit überraschende Konstrukte. Hier möchte ich auf die Unterschiede zu Java eingehen, die aus meiner Erfahrung heraus relevant sind.
Swift und Java – Welche Konzepte sind interessant?
Für Java-Entwickler ist Swift auch deshalb interessant, weil einige Konzepte durchaus auch in einer zukünftigen Java-Version Einzug halten könnten. Weiterhin gibt es doch eine Reihe von Besonderheiten, die den Einstieg in Swift erschweren könnten.
Konsequente Type Inference
Swift ist wie Java streng und statisch typisiert. Damit prüft der Swift-Compiler, dass einer einmal deklarierten Variable kein Wert eines anderen Datentyps zugewiesen werden kann.
Allerdings ist eine Typ-Angabe bei der Deklaration optional; der Typ kann meistens aus dem Typen der Zuweisung bestimmt werden:
var message = "Hello" //message is a String
message = "Hello!" //OK
//message = 42 //Compiler Error
var message2:String //No type inference
Optionals
Sehr gut gelöst ist meiner Meinung nach der Umgang mit Null-Werten, in Swift nilgenannt. Einer Variablen muss ein Nicht-Null-Wert zugewiesen werden, es sei denn, sie wird explizit als Optional-Typ deklariert:
var message = "Hello" //message non optional String
//message = nil //Compiler error
var message2:String? = "Hello" //message2 an optional String
message2 = nil //OK
Optionals sind in Swift eigene Typen, so dass der Compiler bei Zuweisungen die normale Typ-Prüfung durchführt und Fehler erkennt:
//message = message2 //Compiler error: String? not of type String
Optionale Typen müssen vor ihrer weiteren Verwendung “ausgepackt”=unwrapped werden. Dafür gibt es in Swift zwei Möglichkeiten:
Explizites Unwrap mit dem !-Operator
Sicheres Unwrap über die if -let -Konstruktion:
message = message2!
if let x = message2 {
print (x)
}
Obwohl diese Sequenzen für einen Java-Entwickler erst einmal merkwürdig aussehen liegt der Vorteil auf der Hand: Bereits der Compiler erkennt Zuweisungen von Null-Werten, so dass der Entwickler auf null-Prüfungen oder das Fangen einer NullPointerException verzichten kann.
Und dann haben wir noch das “Optional Chaining” beim Zugriff auf Eigenschaften eines Objekts:
if (message2!.hasPrefix("H"){ //Unsafe
//...
}
if (message2?.hasPrefix("H"){ //Safe
//...
}
Falls message2 nil sein sollte wird die hasPrefix-Methode nicht ausgeführt.
Klassen und Strukturen in Swift
Swift kennt zwei unterschiedliche Definitionen eines benutzerdefinierten Datentyps: Klassen und Strukturen.
struct Address{
var city: String, street: String
}
class Person{
private var name:String
init(name: String){
self.name = name
}
var Name: String{
get {
return name
}
set {
print ("setting lastname...")
name = newValue
}
}
func info() -> String {
var greeting = "Hello, my name is \(name)"
return greeting
}
}
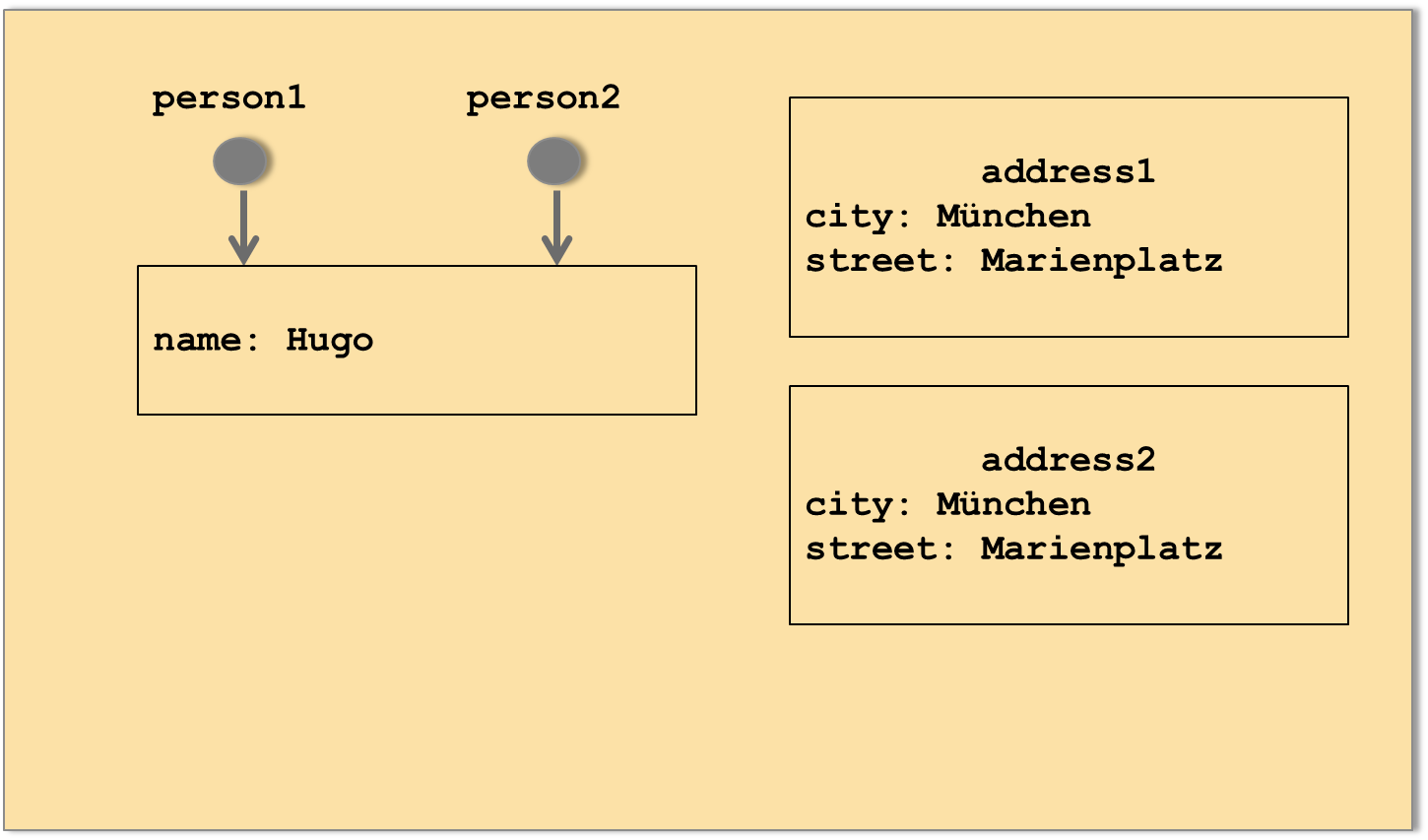
Während Instanzen von Klassen wie in Java stets über Referenzen angesprochen werden, werden Strukturen immer als Werte angesehen:
let address1 = Address(city: "München", street: "Marienplatz")
let address2 = address1
let person1 = Person(name: "Hugo")
let person2 = person1
Der Unterschied zwischen Strukturen und Klassen
Ganz besonders verwirrend für Java-Entwickler ist, dass alle Collections-Implementierungen in Swift als Strukturen realisiert wurden!
Weitere Besonderheiten sind eher unter “syntactic sugar” zu sehen:
Einfache Definition von Properties durch get– und set-Blöcke
Bei Strukturen werden die Konstruktoren automatisch angelegt
Extensions
Alle Klassen und Strukturen sind in Swift “Open for Extension”. Das bedeutet, dass auch ohne Vererbung vorhandene Klassen jederzeit erweitert werden können. Nur zur Klarstellung: Dies gilt selbstverständlich auch für die Klassen der Standard-Bibliothek!
Zur Definition wird das Schlüsselwort extension benutzt. Im Folgenden eine (zugegebenermaßen triviale) Erweiterung der Person-Klasse sowie ein neuer Konstruktor für String:
Die Swift-Installation enthält eine REPL, so dass Sequenzen und einfache Anwendungen auch ohne Installation einer Entwicklungsumgebung ausgeführt werden können.
Schnittstellen heißen in Swift protocol, nicht interface.
Mit der String Interpolation werden Variablen bzw. Ausdrücke direkt in Zeichenketten ausgewertet:
let multiplier = 3.0
let message = "\(multiplier) times 2.5 is \(Double(multiplier) * 2.5)"
// message is "3 times 2.5 is 7.5"
Operatoren können jederzeit geändert oder für eigene Datentypen definiert werden
func + (left: Int, right: Int) -> Int{ //just for fun
return left - right
}
func == (left: Person, right: Person) -> Bool{ //all people are equal
return true
}
func + (left: Person, right: Person){ //adding to people = marriage, suggestions for '-'?
left.marry(right)
}
Auch neue Operatoren sind einfach zu deklarieren. So wird im folgenden Beispiel das Unicode-Zeichen für das Herz-Symbol als Operator zwischen zwei Personen definiert:
Die im Artikel beschriebenen Code-Fragmente stehen über meinen GitHub-Account zur freien Verfügung und können gerne für eigene Experimente benutzt werden. Die Sourcen gibt es hier.
Die Beispiele benötigen eine Swift-Installation, ich habe hierzu die Ubuntu-Installation benutzt.
Was steckt eigentlich hinter dem “Project Lombok”? Jeder Java-Entwickler kennt das Problem bei der Erstellung einer einfachen Datenstruktur. Die eigentliche Modellierung und Definition der Attribute einer Klasse ist erst einmal einfach:
public class Person {
private String name;
private int height;
}
Anschließend müssen dann aber erst einmal aufwändig weitere notwendige Elemente geschrieben werden:
Getter- und Setter-Methoden
Konstruktoren
hashCode und equals
toString
public class Person {
private String name;
private int height;
@Override
public String toString() {
return "Person [name=" + name + ", height=" + height + "]";
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + height;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (height != other.height)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
public int getHeight() {
return height;
}
public void setHeight(int height) {
this.height = height;
}
public String getName() {
return name;
}
public Person(String name, int height) {
super();
this.name = name;
this.height = height;
}
}
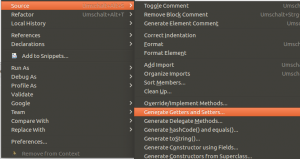
Ohne die Hilfe einer Entwicklungsumgebung wie Eclipse, IntelliJ oder ähnliches wäre dieser Aufwand absurd hoch!
Ausschnitt des Kontext-Menüs zur Code-Generierung in Eclipse
Die Intention des Lombok-Projekts ist es, diesen Aufwand zu vermeiden. Insbesondere bei Änderungen der Datenstruktur müssten ja sonst alle diese Aktionen nochmals neu ausgeführt werden, damit Inkonsistenzen vermieden werden. Mit Lombok muss der Entwickler nur noch Annotationen definieren, die bei jedem Compiler-Lauf neu ausgewertet werden und folglich den aktuellen Stand repräsentieren.
Ein Beispiel mit Project Lombok
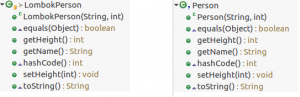
Betrachten wir doch einmal das Outline der oben dargestellten Klasse Person und vergleichen diese mit dem der Klasse LombokPerson
Ein Vergleich der Struktur zweier Klassen
Selbst bei genauer Betrachtung lässt sich hier, außer dem Namen der Klasse, kein Unterschied erkennen. Nun aber der Quellcode der Klasse LombokPerson:
import lombok.AllArgsConstructor;
import lombok.Data;
@Data
@AllArgsConstructor
public class LombokPerson {
private final String name;
private int height;
}
Das ist tatsächlich alles! Keine Konstruktoren, keine Setter etc. Das alles wurde automatisch an Hand der Annotationen erzeugt.
Details zur Arbeitsweise
Lombok stellt einen Annotation Processor zur Verfügung, der die notwendigen Code-Elemente automatisch erstellt. Dafür ist es nur notwendig, die lombok.jar dem Projekt hinzuzufügen und über die IDE das Annotation Processing zu aktivieren. Dann wird der Code generiert und anschließend compiliert.
Falls der Entwickler tatsächlich den generierten Java-Code benutzen möchte, kann hierfür delombok benutzt werden.
Die Code-Generierung kann durch die Angabe weitere Annotationen entsprechend fein angepasst werden. Damit können beispielsweise die in hashCode und equals auszuwertenden Attribute definiert oder der parameterlose Konstruktor generiert werden.
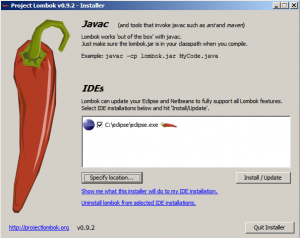
Zur Integration in Entwicklungsumgebungen steht in der lombok.jar eine ausführbare Installationsroutine zur Verfügung.
Der Lombok-Installer, hier für eine Eclipse-Installation
Selbstverständlich kann Lombok auch in automatisierte Buildprozesse integriert werden. Für einen Maven-getriebenen Prozess genügt es beispielsweise, die Abhängigkeit auf Lombok in der POM einzutragen:
Mit Lombok steht meiner Meinung nach ein wirklich sinnvolles Werkzeug zur Verfügung, das den Aufwand bei der Erstellung von Java-Datenklassen deutlich verringert. Programmierern, die sich auch im C#-, Swift oder Groovy-Umfeld bewegen, wird diese Art der Entwicklung sehr bekannt vorkommen. Java ist in diesem Bereich selbst in der Version 8 immer noch ziemlich altbacken, überdies ist eine echte Verbesserung leider auch in der Java 9 -Roadmap nicht erkennbar. Lombok wird deshalb auch noch mittelfristig sinnvoll eingesetzt werden.
Mit den “Experimental Features” werden weitere hochinteressante Elemente eingeführt, die allerdings teilweise einen Überlapp zur Aspekt-orientierten Programmierung aufweisen. Ob diese Annotationen in eigenen Projekten sinnvoll benutzt werden können muss individuell entschieden werden. Nicht vergessen: Project Lombok ist Open Source und folglich Community-getrieben! Welche Richtung dieses Projekt in Zukunft nehmen wird kann deshalb jeder aktiv mit beeinflussen.
Im letzten Teil dieser Serie programmieren wir einen RESTful Web Service mit Spring Boot und stellen diesen über ein Docker-Image zur Verfügung. Dabei stützen wir uns auf den im dritten Teil beschriebenen Build-Prozess.
Spring
Was ist Spring Boot?
Mit Hilfe von Spring Boot können auch komplexe Server-Anwendung als einfaches Java-Archiv ausgebracht und gestartet werden. Dazu werden durch einen ausgefeilten Build-Prozess die Anwendungsklassen zusammen mit allen notwendigen Server-Bibliotheken in ein einziges ausführbares Java-Archiv gepackt.
Der Build-Prozess selbst wird wie üblich mit Hilfe eines Maven-Parents definiert. Dieser wird von der Spring-Community zur Verfügung gestellt.
Benutzen wie dieses POM als Parent für das im 3. Teil der Artikelreihe benutzten Parents, so haben wir den Docker- und den Spring-Boot-Build vereint. Mehr ist tatsächlich nicht zu tun! Im folgenden ist die vollständige Parent-POM dieser Anwendung gegeben, ergänzt um die (hier noch nicht benutzten) Abhängigkeiten zu Spring Data JPA und einer MySQL-Datenbank.
RESTful Web Services werden in Java meistens mit Annotationen realisiert. Dabei wird eine URL auf eine Java-Methodensignatur abgebildet. Dies erfolgt meistens durch Annotationen, entweder mit JAX-RS oder mit den RequestMappings aus Spring-MVC. Im folgenden Beispiel benutzen wir den zweiten Ansatz:
Diese Java-Klasse kann aus Eclipse heraus sofort gestartet werden und anschließend beispielsweise mit Hilfe des curl-Kommandos getestet werden:
curl -X GET http://localhost:8080/echo/Hello
Ein Maven-Build des Projekts erzeugt das Java-Archiv bzw. lädt es in das Artefakt-Repository
mvn package mvn deploy
Ein Aufruf ist dann unter der Angabe des Java-Archivs möglich: java -jar org.javacream.training.rest.spring.basic-0.1.0.jar
Natürlich kann das Archiv auch unbenannt werden, dann ist der Aufruf noch einfacher: java -jar app.jar
Wichtig ist hier, dass das gebildete Artefakt alle notwendigen Bibliotheken mitbringt, um den Web Server für die http-Requests zu starten. Das Archiv ist vollständig.
Der Docker-Build
Zum Erstellen des Docker-Images brauchen wir nun nur noch ein Dockerfile! Dessen Inhalt ist aus den vorherigen Ausführungen heraus allerdings schon fast trivial:
Als Basis nehmen wir eine Java-Grundinstallation.
Dann kopieren wir noch das generierte Artefakt und
definieren als EntryPoint den Java-Aufruf.
Eine Port-Mapping oder ein Mounten des Log-Directories des Containers ist selbstverständlich noch möglich.
FROM openjdk:latest
ADD org.javacream.training.rest.spring.basic-0.0.1.jar app.jar
ENTRYPOINT java -jar app.jar
Der RESTful Web Service wird nun ganz normal gestartet:
docker run --rm javacream:org.javacream.training.rest.spring.basic:0.0.1
und könnte wieder über curl getestet werden.
Soll das Image noch auf das Artefakt-Repository geschoben werden genügt ein
mvn docker:push
Das funktioniert aber natürlich nur, wenn ein eigenes Repository betrieben wird. Aber auch dieses Problem ist bereits gelöst: Nexus und Artefactory unterstützen Docker ganz analog zu Java-Artefakten.
Damit steht das Image anderen Entwicklern, der Test&QS-Abteilung oder den System-Administratoren der Produktionsumgebung zur Verfügung.
Dieser Artikel ist der Abschluss meiner Reihe über “Docker und Java”. Wer mehr über den Einsatz von Java in einer Microservice-Systemarchitektur lesen möchte: Im Frühjahr 2017 erscheint eine Reihe von Artikeln zum Thema “Microservice-Architekturen mit Docker”.