Bereits mit der Version 1.4 von Java wurde das nio-Paket eingeführt. Dies enthält als Hauptbestandteil Klassen, die einen Buffer, also einen Container für Daten enthalten. Diese Buffer-Implementierungen in Java können für eine sehr effiziente In-Memory-Datenhaltung genutzt werden, insbesondere kann aber auch das in einem vorherigen Artikel bereits vorgestellte Off-Heap-Memory benutzt werden.
Ein Buffer im Heap-Speicher
Im Package java.nio sind verschiedene-Buffer-Implementierungen vorhanden, beispielsweise auch ein ByteBuffer. Mit diesem können wir nun eine weitere MegyByte-Klassen definieren:
package org.javacream.util.memory;
import java.nio.ByteBuffer;
public class ByteBufferMegaByte implements MegaByte {
private ByteBuffer byteBuffer;
public ByteBufferMegaByte(int megaByte) {
byteBuffer = ByteBuffer.allocate(megaByte * 1024 * 1024);
}
@Override
public void set(int i, byte value) throws NoSuchFieldException, IllegalAccessException {
byteBuffer.put(i, value);
}
@Override
public int get(int i) throws NoSuchFieldException, IllegalAccessException {
return byteBuffer.get(i);
}
@Override
public long size() {
return byteBuffer.capacity();
}
}
Auch hier wird der normale Heap-Speicher der JVM genutzt:
Das nio-API sieht übrigens keine explizite Möglichkeit vor, den Speicher des Buffers wieder freizugeben. Dies übernimmt finalize, eine zugegebenermaßen etwas wacklige und undefinierte Arbeitsweise. Inwieweit zukünftige Java-Versionen hier Abhilfe schaffen ist noch nicht abzusehen.
Quellcode
Der Quellcode der Beispiele ist in einem GitHub-Repository des Autors abgelegt und kann von dort geladen werden.
Die Java Virtual Machine organisiert und verwaltet die Objekte einer Anwendung selbst im so genannten Heap-Speicher. Diese wurde im Beitrag über Referenzen und Objekte beschrieben. Ein automatischer Hintergrundprozess, die Garbage Collection, entfernt automatisch nicht mehr referenzierbare Objekte und bereinigt somit den Speicher.
“Native Memory” bzw Off-Heap Memory in Java ist jedoch ebenfalls möglich!
Was ist “Off-Heap Memory”?
Das Off-Heap Memory ist, wie der Name auch sagt, außerhalb der des Heaps angesiedelt und wird deshalb nicht von der Garbage Collection bereinigt. Weiterhin ist es für einen Programmierer nicht möglich, Objekte direkt im Off-Heap Memory zu instanzieren. Damit ist die Benutzung deutlich komplexer und auch mit mehr Fehlerpotenzial behaftet als das Referenzen-Modell.
Warum “Off-Heap Memory”?
Damit scheint die Benutzung dieses Speichers ein Rückschritt zu sein: Der Programmierer hat deutlich mehr Verantwortung, nicht mehr notwendige Daten zu identifizieren und dann auch selber zu löschen. Weiterhin müssen auch alle abhängigen Objekte erkannt werden. Es stellt sich deshalb die Frage, was denn Szenarien sein könnten, dieses native Memory zu benutzen.
Dafür kann aber sofort ein eingängiges Beispiel gefunden werden: Ein Java-basierter Cache!
Zur Ablage der Cache-Einträge ist das Native Memory nämlich wunderbar geeignet:
Die Gültigkeit von Daten, die im Cache abgelegt werden, ist mit Stunden oder sogar noch viel länger aus Sicht der Frequenz der Garbage-Collection wirklich sehr lange. Damit prüft der Collector diese Objekte immer wieder darauf, ob sie nun endlich gelöscht werden können. Eine sinnlose und damit ineffiziente Verschwendung von CPU-Ressourcen.
Cache-Daten sind häufig eher flache Datenstrukturen und nicht komplexe Objektgrafen.
Der Lebenszyklus der Daten ist simpel: Mit put werden die Daten geschrieben, mit get gelesen und mit remove gelöscht. Eine einfach zu programmierende Sequenz.
In zwei anderen Artikeln wird das Off-Heap-Memory mit Java-Beispiele genutzt: Einmal mit der internen Klasse Unsafe und dann mit den Buffern des NIO.
Die Umsetzung des Off-Heap Memories in Java hat eine lange Historie, die verschiedene Lösungsstrategien hervorgebracht hat.
Benutzung eines RAM-Drives
Als auch heute noch durchaus gebräuchliche Möglichkeit hat sich die Verwendung des Dateisystems etabliert. “Moment”, wird der aufmerksame Leser anmerken, “das hat doch nichts mit RAM zu tun”. Nun, stimmt nicht ganz: Unter Linux ist /tmp in der Regel immer im RAM abgelegt. Benutzt damit ein Java-Programm dieses Verzeichnis, werden die darin abgelegten Dateien im Endeffekt im Speicher gehalten.
Unsafe
Diese Lösung benutzt eine sehr skurrile Klasse aus der Java-Bibliothek: sun.misc.Unsafe. Diese Klasse, deren Namen ihre Verwendung demotivieren soll, ermöglichte bereits seit der ersten Java-Version einen sehr direkten Zugriff auf den Speicher der JVM. Ein Objekt ohne Konstruktoraufruf erstellen? Wird gemacht. Und dann thematisch passend zu diesem Beitrag: Off-Heap Memory anfordern und verwalten. Die Benutzung sei an folgendem Beispiel demonstriert. Als erstes programmieren wir eine simple Klasse, die Megabytes an Daten in einem Array allokiert:
package org.javacream.util.memory;
import java.io.Serializable;
public class ByteArrayMegaByte implements Serializable, MegaByte {
private static final long serialVersionUID = 1L;
private byte[] megabyte;
public byte[] getMegabyte() {
return megabyte;
}
public ByteArrayMegaByte(int mByte) {
megabyte = new byte[mByte * 1024 * 1024];
}
@Override
public void set(int i, byte value) throws NoSuchFieldException, IllegalAccessException {
megabyte[i] = value;
}
@Override
public int get(int i) throws NoSuchFieldException, IllegalAccessException {
return megabyte[i];
}
@Override
public long size() {
return megabyte.length;
}
}
Im folgenden Testfall wird diese Klasse benutzt, um Heap-Speicher zu belegen. Der Testfall erzeugt hierzu Konsolenausgaben, die die Belegung des Speichers beweisen:
Hier ist der Heap-Speicher überhaupt nicht betroffen!
Um zu zeigen, dass Off-Heap-Memory benutzt wird, wird der Test mit der JVM-Option
-XX:NativeMemoryTracking=detail gestartet und blockiert, kann mit
jcmd <pid> VM.native_memory
unter Angabe der Process-Id (mit jps) ein detaillierter Auszug des Gesamtspeichers der JVM ausgegeben werden. Eine exemplarische Ausgabe zeigt die etwa 500MByte des reservierten internen Speichers:
Die Historie der Unsafe-Klasse ist übrigens recht spannend: Schon der Paketname zeigt, dass diese Klasse niemals für ein “offizielles API” gedacht war. Deshalb existiert hierfür auch kein Javadoc. Oracle wollte dann diese Klasse aus der Bibliothek entfernen, was aber auf den massiven Widerstand von Server-Herstellern, insbesondere eben von Caching-Lösungen stieß. Deshalb hat Oracle davon abgesehen, diese Klasse zu entfernen, arbeitet aber an einer offiziellen Lösung, die eine einfache Migration weg von sun.misc.Unsafe ermöglichen soll. Stand heute ist diese Klasse aber immer noch im aktuellen Java-Release vorhanden.
Buffer des NIO
Die einfachste Art der Programmierung mit dem Off-Heap-Memory ist jedoch sicherlich das mit Java 1.4 eingeführte Paket java.nio und die darin enthaltenen Buffer-Implementierungen. Diese werden in einem weiteren Artikel beschrieben.
Quellcode
Der Quellcode der Beispiele ist in einem GitHub-Repository des Autors abgelegt und kann von dort geladen werden.
Objekt-orientierte Programmierung ist bekanntermaßen ein sehr verbreitetes Konzept zur Modellierung komplexer Anwendungen. Die Programmiersprache Java hat bereits seit ihrer Einführung 1995 dieses Konzept aufgenommen. Auch die Laufzeitumgebung, also die Java Virtual Machine (JVM) berücksichtigt dieses Konzept und implementiert deshalb ein Speichermodell, das auf Referenzen und Objekte ausgerichtet ist.
Stack und Heap
Der Speicher der Java Virtual Machine ist in einen Stack- und einen Heap-Bereich unterteilt.
Stack und Heap der JVM
Diese Unterteilung ist zwar etwas grob, genügt aber für die folgende Betrachtung völlig.
Jede Java-Methode bekommt ihren eigenen Stack-Bereich zugeordnet. Innerhalb des Stacks werden sämtliche lokalen Variablen abgelegt. Wie im Objekt-orientierten notwendig sind diese Variablen in Java stets Referenzen auf Objekte. Diese werden im Heap-Bereich abgelegt.
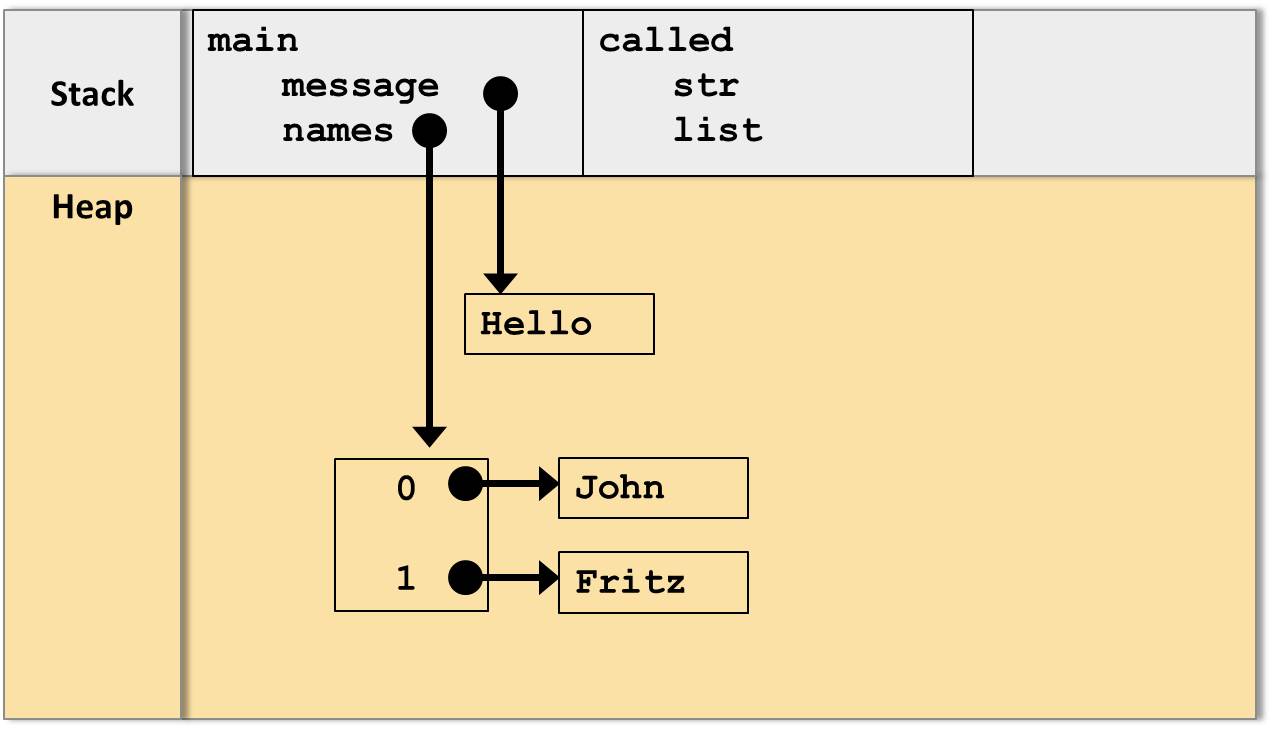
Dies sei am Beispiel der folgenden main-Methode aufgezeigt:
Wie erfolgt nun jedoch die Übergabe der lokalen Variablen message und names in die Parameter str und list?
Wie werden die Parameter belegt?
Dazu wird die JVM die Werte der Referenzen als Kopie übergeben, also ein “CallByValue”-Verhalten auf der Ebene der Referenzen:
Copy By Value mit Referenzen
Im Endeffekt zeigen die Referenzen auf die selben Objekte im Heap.
Zuweisung von Werten
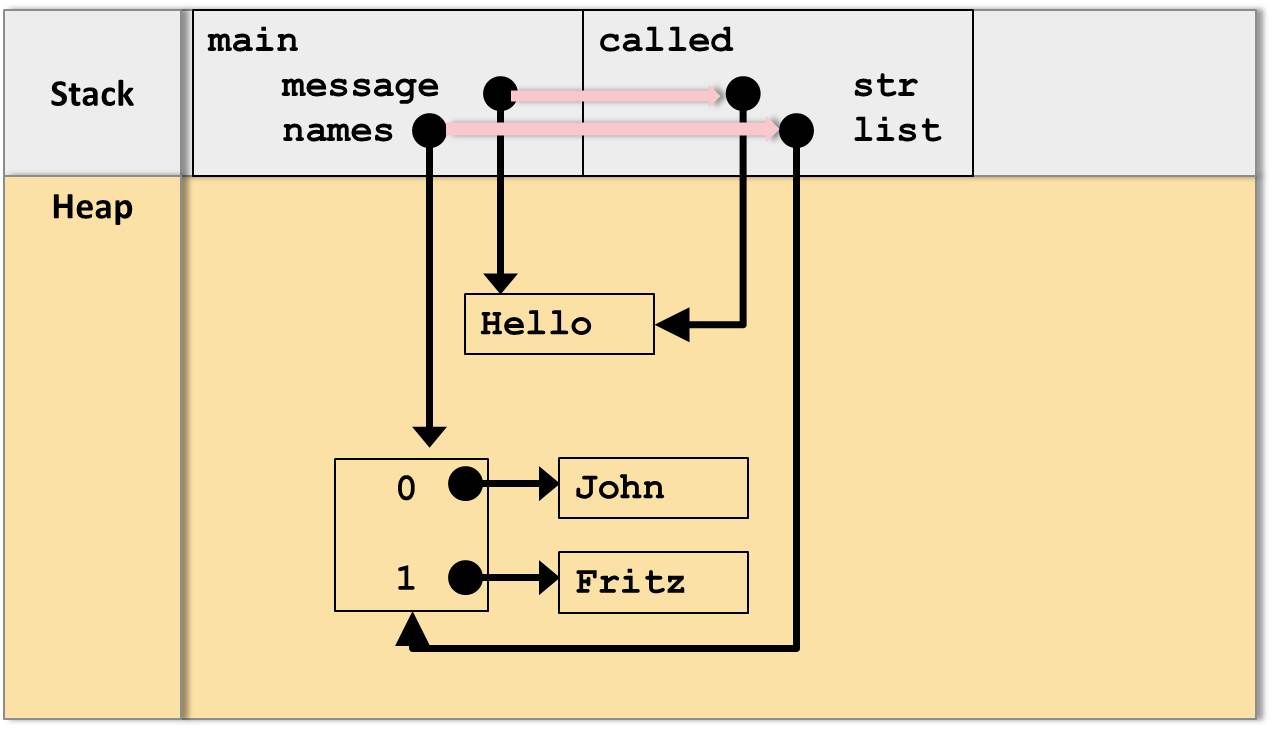
Was passiert aber nun, wenn in der aufgerufenen Methode den Parametern neue Werte zugewiesen werden? Hier ergibt sich ein feiner aber unglaublich wichtiger Unterschied: Belegen wir den Parameter str einfach mit einem neuen Wert, z.B. mit
str = "Goodbye";
so wird die Variable im Stack einfach mit einer Referenz auf das neue Objekt im Heap überschrieben:
Zuweisung eines neuen Wertes an den Parameter str
Wichtig hier ist, dass in der aufrufenden main-Methode die Variable message davon völlig unbeeinflusst bleibt.
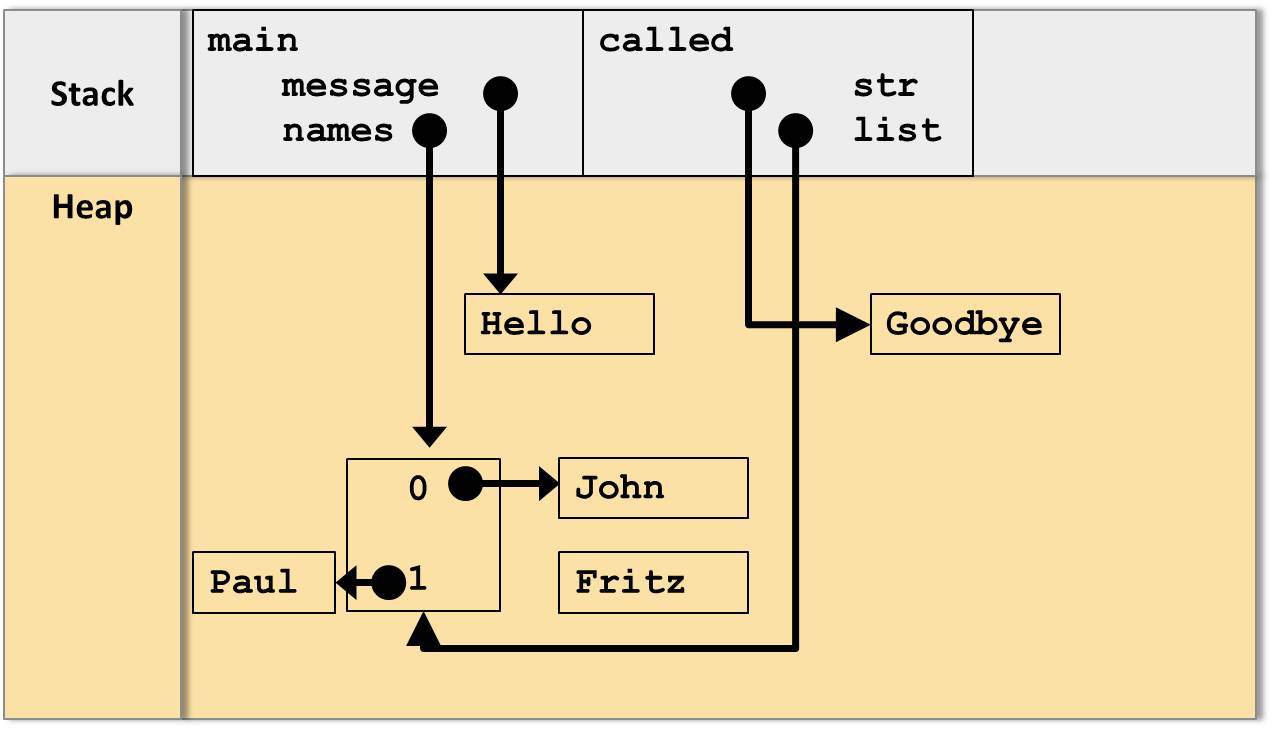
Was passiert aber, wenn wir die Referenz auf das Array benutzen, um beispielsweise den Wert des zweiten Elements mit Index 1 auf “Paul” zu setzen?
list[1] ="Paul";
Nun ergibt sich ein anderes Bild:
Zuweisung eines neuen Wertes an das zweite Element der Liste
Hier ist klar ersichtlich, dass diese Änderung des Array-Objekts innerhalb der Methode called auch direkt Auswirkungen auf die aufrufende main-Methode hat: Nachdem die Methode called terminiert ist referenziert auch die Variable message auf das Array, dessen zweites Element nun auf “Paul” zeigt.
Also innerhalb von main
public static void main(String[] args){
String message = "Hello";
String[] names = {"John", "Fritz"};
called(message, names);
System.out.println(names[1]); //-> Paul
}
Zusammenfassung und Ausblick
Durch die Betrachtung des Speichermodells der Java Virtual Machine wird die Arbeitsweise eines Objekt-orientierten Programms unter Verwendung von Referenzen klar und verständlich. Das komplette Beispiel liegt als fertiges Eclipse-Projekt vor und enthält zusätzlich Konsolen-Ausgaben, die den Ablauf des Programms demonstrieren. Selbstverständlich kann aber auch der Eclipse-Debugger benutzt werden, um die Ausführung nachzuvollziehen.
Allerdings sind sicherlich auch noch einige Punkte nicht fundiert behandelt worden:
Das vorgestellte Speichermodell ist stark vereinfacht. Wie schaut es denn tatsächlich aus?
Was passiert eigentlich mit dem armen Objekt “Fritz”, das nun komplett losgelöst im Heap vorhanden ist?
Diese beiden Punkte werden in einem folgenden Artikel, der den Garbage Collector der JVM als Thema hat, behandelt.
Im vorherigen Artikel wurde die prinzipielle Arbeitsweise einer Blockchain allgemein diskutiert. Eine Blockchain mit Java zu implementieren ist prinzipiell nicht sonderlich schwer und wird im Folgenden gezeigt.
Einige Hinweise sind vorab notwendig, um beim Leser keine übertriebenen Erwartungen zu wecken:
Diese Java-Klassen alleine stellen natürlich kein funktionierendes verteiltes Datenbanksystem dar. Dazu fehlt das Netz der Server-Knoten.
Eine konkrete Validierung der Records, die in einen Block eingestellt wird erfolgt nur rudimentär. Dies ist selbstverständlich eine Anforderung, die aus einer fachlichen Spezifikation entnommen werden muss. Eine Blockchain für Gesundheitsdaten hat komplett andere Regeln als eine für Finanz-Transaktionen.
Komplett weggelassen wurde das Thema “Consense Modelle”, also beispielsweise ein “Proove of Work” wie beim Bitcoin-Mining.
Das Beispielprojekt
Die im Folgenden gezeigten Beispiele sind im GitHub-Account des Autoren abgelegt. Das Projekt ist frei verfügbar und kann für eigene Demonstrationen und Ergänzungen gerne benutzt werden.
Hashing
Zwingend notwendig für die Arbeit einer Blockchain ist die Bestimmung der hochwertigen Hashes. Dieses Problem ist in der Java-Distribution schon lange gelöst, dafür gibt es die Klasse MessageDigest. Nachdem diese jedoch etwas sperrig in der Benutzung ist, wird das DigestUtil aus dem Apache Commons Codec-Projekt benutzt:
Placeholder
Der Test beweist, dass die Anforderungen an die Hash-Erzeugung erfüllt sind:
Unabhängig von der Länge der Eingangsdaten sind alle Hash-Werte gleich lang, nämlich 32 Zeichen.
Die Hash-Werte zweier minimal unterschiedlicher Eingangsdaten weisen keinerlei Ähnlichkeiten auf.
Der Wertebereich des Hashes ist so groß, dass zufällige Identitäten ausgeschlossen werden können.
Der Block
Die Implementierung eines für die Chain geeigneten Blocks ist tatsächlich sehr einfach. Ein Block enthält
die Daten, die für ein einfaches Beispiel beliebig sein können
den Hashwert des Vorgängers
einen eigenen Hashwert
einen Zeitstempel
Eine direkte Umsetzung zeigt folgende Klasse:
Placeholder
Eine korrekte Arbeitsweise beweist dieser Unit-Test:
Placeholder
Die Blockchain
Die Blockchain-Implementierung macht folgendes:
Die Klasse hält eine Liste von Blöcken
Eine add-Methode nimmt hinzuzufügende Daten entgegen. Diese werden exemplarisch validiert und, nach Erfolg, in einen Block umgesetzt. Dieser wird anschließend in der Liste hinzugefügt.
Mit Angabe eines Indexes kann ein bestimmter Datensatz wiederum gelesen werden.
Ebenso kann eine Liste aller Daten erhalten werden.
Placeholder
Im Endeffekt bildet die verkettete Liste der Blöcke einen Hash-Baum oder Merkle-Tree.
Auch hier zeigt ein Test das korrekte Funktionieren der Implementierung:
Placeholder
Der Versuch eines Angriffs
Wie kann nun ein Angriff auf diese Blockchain erfolgen? Bevor der Versuch eines Angriffs näher erläutert wird ist es aber wichtig, sich bewusst zu machen, dass die Informationen, die in der Chain abgelegt sind, in der Praxis auf vielen Knoten eines verteilten Systems abgelegt sein werden. Das bedeutet damit, dass der Angreifer seine Attacke nicht nur gegen einen Rechner fahren muss, sondern im Endeffekt gegen eine Majorität der Rechner. Dies macht die Sache schon deutlich komplexer. Andererseits müssen die Knoten ihre Daten untereinander synchronisieren, was durch Abhören der Netzwerkkommunikation einen erstmals durchaus vielversprechenden Angriffsvektor definiert.
Hat der Angreifer Zugriff auf einen oder mehrere Blöcke, so können die darin enthaltenen Informationen ausgelesen werden. Um ein Bloßlegen sensibler Daten zu verhindern, müssen damit die im Block enthaltenen Daten zusätzlich verschlüsselt werden. Das ist in dieser einfachen Implementierung nicht gegeben, in der Praxis aber ein eher einfach zu lösendes Problem.
Erweitern wir nun den Zugriff des Angreifers: Dieser hätte einen Server-Knoten komplett unter seine Gewalt bekommen. Und wir gehen noch weiter: Die Informationen der Blöcke sind im Klartext bekannt. Diese Situation wäre in einer klassischen Architektur vergleichbar mit einem korrumpierten Datenbank-Administrator, der den Datenbank-Host kontrolliert. Dass damit bereits beträchtlicher Schaden angerichtet ist, ist vollkommen klar. Aber fast noch schlimmer wäre es nun, die Daten manipulieren zu können. So könnte beispielsweise versucht werden, eine wichtige Information nachträglich zu ändern. Was muss der Angreifer alles machen:
Der Block muss die geänderte Information gesetzt bekommen.
Er muss einen neuen Hash erzeugen und auf diese Art und Weise einen komplett neuen, konsistenten Block erzeugen. Dies ist bereits die erste Komplikation.
Nun muss der manipulierte Block in die Blockchain integriert werden. Und nun wird es wirklich kompliziert: Denn nicht nur der eine manipulierte Block muss geändert werden, sondern auch alle (!) Nachfolger. Denn diese beziehen sich auf einen Parent-Block, der so ja gar nicht mehr in der Chain enthalten ist. Der Aufwand für den Angreifer und damit die Wahrscheinlichkeit, dass die Manipulation entdeckt wird steigt bereits hier drastisch.
Und zum Schluss muss der Angreifer die anderen Knoten des verteilten Systems “überzeugen”, diese Änderungen komplett zu übernehmen.
Schon der dritte Punkt ist so aufwändig zu realisieren, dass die Wahrscheinlichkeit eines Erfolgs des Angriffs drastisch sinkt. Punkt 4 übersteigt endgültig die Fähigkeiten eines realistischen Angreifers.
Der folgende Test simuliert einen Angreifer, der die Java-Anwendung angreift. Der Versuch ist erfolgreich bis zu Punkt zwei, aber mehr auch nicht:
Placeholder
Ausblick
Um ein funktionierendes, auf Blockchain-Technologie basierendes System in Betrieb nehmen zu können fehlen noch
Das verteilte System mit den kommunizierenden Knoten
Authentifizierung, Autorisierung und Verschlüsselung
Eine Implementierung einer fachlich konsistenten Validierung der Block-Daten
Und schließlich noch eine Logik für fachliche Abfragen.