Dokumenten-orientierte Datenbanksysteme sind im Rahmen der NoSQL-Bewegung entstanden und haben sich in den letzten Jahren zu stabilen und etablierten Produkten entwickelt. Im aktuellen Ranking von Datenbanksystemen steht mit der kommerziellen MongoDB ein Document-Store unter den Top 5, aber auch die in einer vollwertigen Community-Edition vorliegende Couchbase ist, wenn auch deutlich schwächer, vertreten.
Was sind Dokumente?
Ein Dokument ist eine Datenstruktur, die ähnlich wie eine Datenbank-Tabelle einem definierten Schema genügt. Allerdings wird dieses Schema von der Datenbank in der Regel nicht über Constraints beim Schreiben des Datensatzes geprüft (“Schema on write”), sondern erst bei Abfragen (“Schema on read”): Dokumente, die der Query entsprechen, werden in die Treffermenge aufgenommen, nicht-passende Dokumente eben nicht. Eine Dokumenten-orientierte Datenbank benötigt deshalb nicht unbedingt verschiedene Tabellen-Definitionen, sondern kann alle Dokumente in einer einzigen Collection oder einem “Bucket” ablegen.
So können beispielsweise in einer Datenbank sämtliche Dokumente einer Reiseagentur (Fluglinien, Flughäfen, aber auch Flugpläne und Routen) gemeinsam abgelegt werden.
Dokumente werden über eine innerhalb der Datenbank eindeutigen Document-ID identifiziert.
Links versus Joins
Im Gegensatz zu einem relationalen Modell unterstützen Dokumente Server-seitige Joins nicht unbedingt. Es ist eher üblich, Dokumente zu Verlinken und damit im Endeffekt dem Client das Nachladen von Assoziationen zu überlassen.
Dokumenten-Formate
Als Quasi-Standard für das Format von Dokumenten hat sich JSON herauskristallisiert. Dies ist einesteils etwas überraschend, da JSON bis heute keinen wirklichen Standard für Links definiert hat. Hier ist XML klar überlegen. Andererseits werden Dokumente sehr häufig im Rahmen einer RESTful Architektur benutzt, so dass in der Praxis als Implementierung http genutzt wird. Und dafür ist JSON die natürliche Wahl.
Clusterbetrieb
Dokumenten-orientierte Datenbanksysteme sind immer auf einen Cluster-Betrieb ausgerichtet. Das ergibt sich klar aus dem Bezug zur NoSQL-Bewegung und damit dem “Big Data”-Umfeld.
Für die Umsetzung eines dynamisch skalierenden Clusters bieten sich zwei Strategien an:
- Sharding: Hier werden die Dokumente auf Grund eines Sharding Keys, der nicht unbedingt der Document-ID entsprechen muss, auf die verschiedene Knoten des Clusters verteilt. Ein zentraler Master oder Router nimmt alle Anfragen entgegen und verteilt diese dann an Hand von Konfigurations-Informationen auf die Knoten, die die Daten enthalten. Die MongoDB ist ein Beispiel für diese Cluster-Architektur. Die folgende Abbildung entstammt der Dokumentation unter https://docs.mongodb.com/manual/core/sharded-cluster-components/:

Ein einfacher Mongo Cluster - Ring Cluster: Hier wird auf den Master und den Konfigurationsserver verzichtet; jeder Knoten des Clusters ist gleichberechtigt. Ein Beispiel hierfür ist der Couchbase Server, siehe https://docs.couchbase.com/server/5.0/architecture/architecture-intro.html:
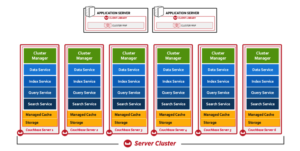
Couchbase Cluster