Eine Spring Data Anwendung mit einem Apache Cassandra Backend ist recht einfach zu erstellen, da Spring Data hierfür ein eigenes Subprojekt etabliert hat. Weiterhin gibt es selbstverständlich einen Embedded Cassandra Server als Bestandteil von Spring Boot. Ein externer Server ist kann über einen Docker-Container realisiert werden, das offizielle Docker-Image liegt auf dem Docker Hub.
Cassandra im Docker-Container
Für eine einfache Test-Anwendung wird eine einzelne Cassandra-Instanz über den Aufruf
docker run --rm --name cassandra -p 9142:9142 cassandra
gestartet. Damit läuft ein einzelner Cassandra-Knoten.
Nach dem Starten des Containers kann eine Konsole im Container geöffnet werden, mit deren Hilfe die Cassandra Shell cqlsh geöffnet werden kann:
docker exec --it cassandra /bin/bash
cqlsh
Damit kann dann für das folgende Beispiel nötige KeySpace sowie die Tabelle angelegt werden:
CREATE KEYSPACE PUBLISHING_KEYSPACE
WITH REPLICATION = {
'class': 'SimpleStrategy',
'replication_factor': 1
};
CREATE TABLE PUBLISHING(
publisher_name text,
title text,
isbn text,
price double,
pages int,
available boolean,
primary key(publisher_name, title, pages)
);
Die Spring Boot Anwendung
Wie üblich ist der Einstiegspunkt in die Spring Boot-Anwendung die pom.xml. Diese definiert neben dem Spring Boot Parent den Starter für Cassandra:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.8.RELEASE</version>
<relativePath /> <!-- lookup parent from repository -->
</parent>
<groupId>org.javacream.training</groupId>
<artifactId>org.javacream.training.apache.cassandra.springboot</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>org.javacream.training.apache.cassandra.springboot</name>
<description>Cassandra project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-cassandra</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
Damit ist die Konfiguration der Anbindung an den im Docker-Container laufenden Datenbankserver einfach:
@EnableCassandraRepositories
@Configuration
public class PublishingConfiguration
}
und die application.properties:
spring.data.cassandra.port=9142
spring.data.cassandra.keyspace-name=PUBLISHING_KEYSPACE
Entity und Repository
Die in der Cassandra-Datenbank abzulegende Datenstruktur wird über Annotationen gemapped:
@Table
public class Book {
@PrimaryKeyColumn(name = "publisher_name", ordinal = 0, type = PrimaryKeyType.PARTITIONED)
private String publisherName;
@PrimaryKeyColumn(name = "pages", ordinal = 2, type = PrimaryKeyType.CLUSTERED)
private int pages;
private double price;
private String isbn;
private boolean available;
@PrimaryKeyColumn(name = "title", ordinal = 1, type = PrimaryKeyType.CLUSTERED)
private String title;
//getter, setter, hashCode, equals, toString
}
Das Repository selbst ist dann eine einfache Schnittstellen-Erweiterung des CassandraRepository:
@Repository
public interface PublishingRepository extends CassandraRepository<Book, String>{
}
Die Anwendung
Die Anwendung selber schreibt nun nur 4 Bücher in die Datenbank:
@Component
public class PublishingApplication {
@Autowired private PublishingRepository publishingRepository;
@PostConstruct public void startApplication() {
Book cassandraInAction1 = new Book("Manning", 100, 19.99, "ISBN-1", false, "Cassandra in Action");
publishingRepository.save(cassandraInAction1);
Book cassandraInAction2 = new Book("Manning", 200, 29.99, "ISBN-2", true, "Cassandra in Action");
publishingRepository.save(cassandraInAction2);
Book cassandraInAction3 = new Book("Manning", 500, 39.99, "ISBN-3", true, "Cassandra in Action");
publishingRepository.save(cassandraInAction3);
Book java = new Book("Manning", 5000, 9.99, "ISBN-4", true, "Java");
publishingRepository.save(java);
}
}
Die geschriebenen Daten können nun einfach über die CQL-Shell abgefragt werden:
cqlsh:publishing_keyspace> select * from publishing where publisher_name='Manning' ;
publisher_name | title | pages | available | isbn | price
----------------+---------------------+-------+-----------+--------+-------
Manning | Cassandra in Action | 100 | False | ISBN-1 | 19.99
Manning | Cassandra in Action | 200 | True | ISBN-2 | 29.99
Manning | Cassandra in Action | 500 | True | ISBN-3 | 39.99
Manning | Java | 5000 | True | ISBN-4 | 9.99
(4 rows)
Oder mit einer zusätzlichen Selektion auf den Titel:
cqlsh:publishing_keyspace> select * from publishing where publisher_name='Manning' and title = 'Cassandra in Action';
publisher_name | title | pages | available | isbn | price
----------------+---------------------+-------+-----------+--------+-------
Manning | Cassandra in Action | 100 | False | ISBN-1 | 19.99
Manning | Cassandra in Action | 200 | True | ISBN-2 | 29.99
Manning | Cassandra in Action | 500 | True | ISBN-3 | 39.99
(3 rows)
Und schließlich noch auf die Seiten:
cqlsh:publishing_keyspace> select * from publishing where publisher_name='Manning' and title = 'Cassandra in Action' and pages = 200;
publisher_name | title | pages | available | isbn | price
----------------+---------------------+-------+-----------+--------+-------
Manning | Cassandra in Action | 200 | True | ISBN-2 | 29.99
(1 rows)
Die folgende Abfrage führt nun jedoch zu keinem sinnvollen Ergebnis:
cqlsh:publishing_keyspace> select * from publishing where pages = 200;
InvalidRequest: Error from server: code=2200 [Invalid query] message="PRIMARY KEY column "pages" cannot be restricted as preceding column "title" is not restricted"
Seminare zum Thema
Weiterlesen

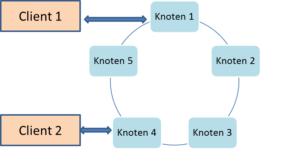
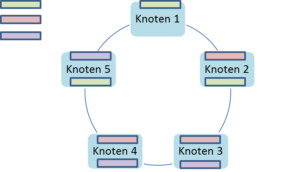
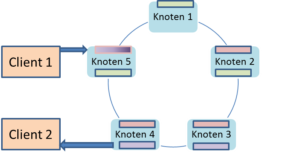 Es dauert eine gewisse Zeit, bis alle beteiligten Knoten des Rings alle Datenänderungen mitbekommen haben. Ist so ein Zeitfenster der Inkonsistenz fachlich möglich, so spricht man von einer BASE-Architektur, in der das E für die “Eventual Consistency” steht. “Eventual” ist hier selbstverständlich mit “letztendlich” zu übersetzen; letztendlich wird ein Ring-Cluster einen konsistenten Zustand erreichen.
Es dauert eine gewisse Zeit, bis alle beteiligten Knoten des Rings alle Datenänderungen mitbekommen haben. Ist so ein Zeitfenster der Inkonsistenz fachlich möglich, so spricht man von einer BASE-Architektur, in der das E für die “Eventual Consistency” steht. “Eventual” ist hier selbstverständlich mit “letztendlich” zu übersetzen; letztendlich wird ein Ring-Cluster einen konsistenten Zustand erreichen.