Objekt-orientierte Programmierung ist bekanntermaßen ein sehr verbreitetes Konzept zur Modellierung komplexer Anwendungen. Die Programmiersprache Java hat bereits seit ihrer Einführung 1995 dieses Konzept aufgenommen. Auch die Laufzeitumgebung, also die Java Virtual Machine (JVM) berücksichtigt dieses Konzept und implementiert deshalb ein Speichermodell, das auf Referenzen und Objekte ausgerichtet ist.
Stack und Heap
Der Speicher der Java Virtual Machine ist in einen Stack- und einen Heap-Bereich unterteilt.
Diese Unterteilung ist zwar etwas grob, genügt aber für die folgende Betrachtung völlig.
Jede Java-Methode bekommt ihren eigenen Stack-Bereich zugeordnet. Innerhalb des Stacks werden sämtliche lokalen Variablen abgelegt. Wie im Objekt-orientierten notwendig sind diese Variablen in Java stets Referenzen auf Objekte. Diese werden im Heap-Bereich abgelegt.
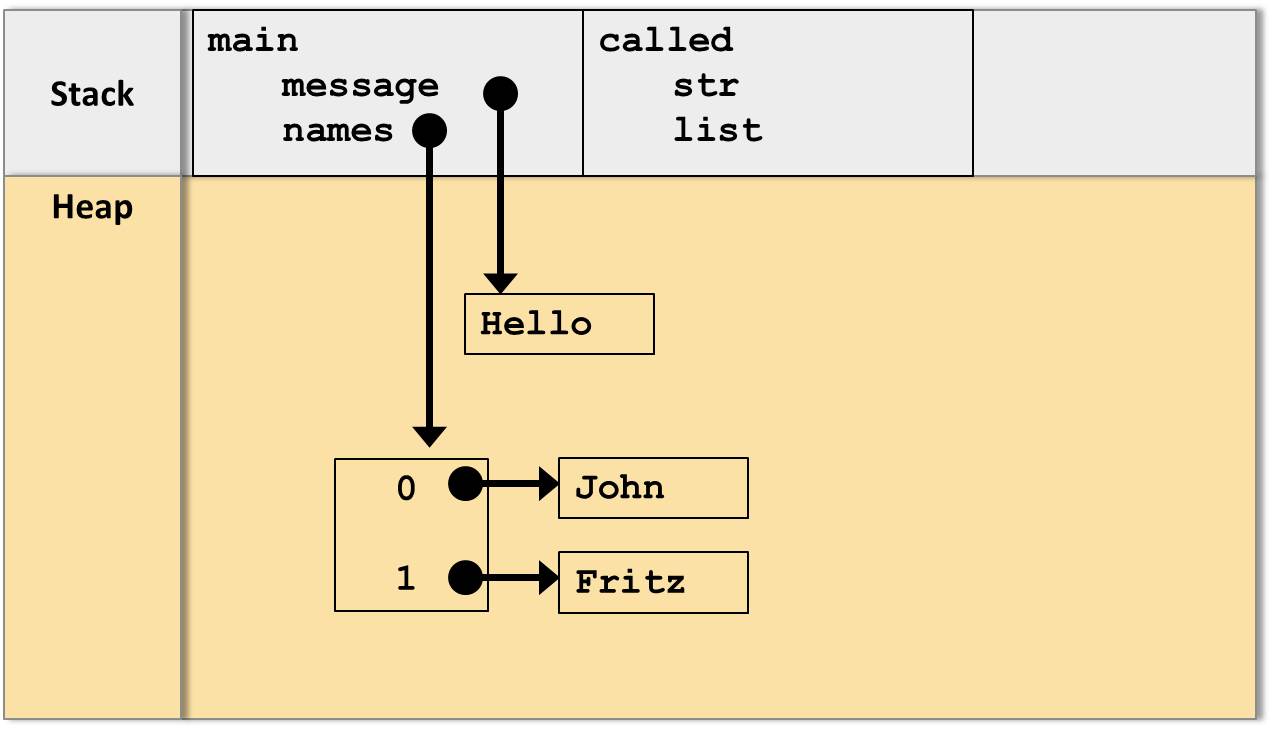
Dies sei am Beispiel der folgenden main-Methode aufgezeigt:
public static void main(String[] args){
String message = "Hello";
String[] names = {"John", "Fritz"};
}Im Speicher der JVM ergibt sich das folgende Bild:

Methodenaufruf
Nun definieren wir eine zweite Methode, called, diesmal mit 2 Parametern
public static void called(String str, String[] list){
}
Diese Methode wird aus main heraus aufgerufen:
public static void main(String[] args){
String message = "Hello";
String[] names = {"John", "Fritz"};
called(message, names);
}Wie erfolgt nun jedoch die Übergabe der lokalen Variablen message und names in die Parameter str und list?

Dazu wird die JVM die Werte der Referenzen als Kopie übergeben, also ein “CallByValue”-Verhalten auf der Ebene der Referenzen:
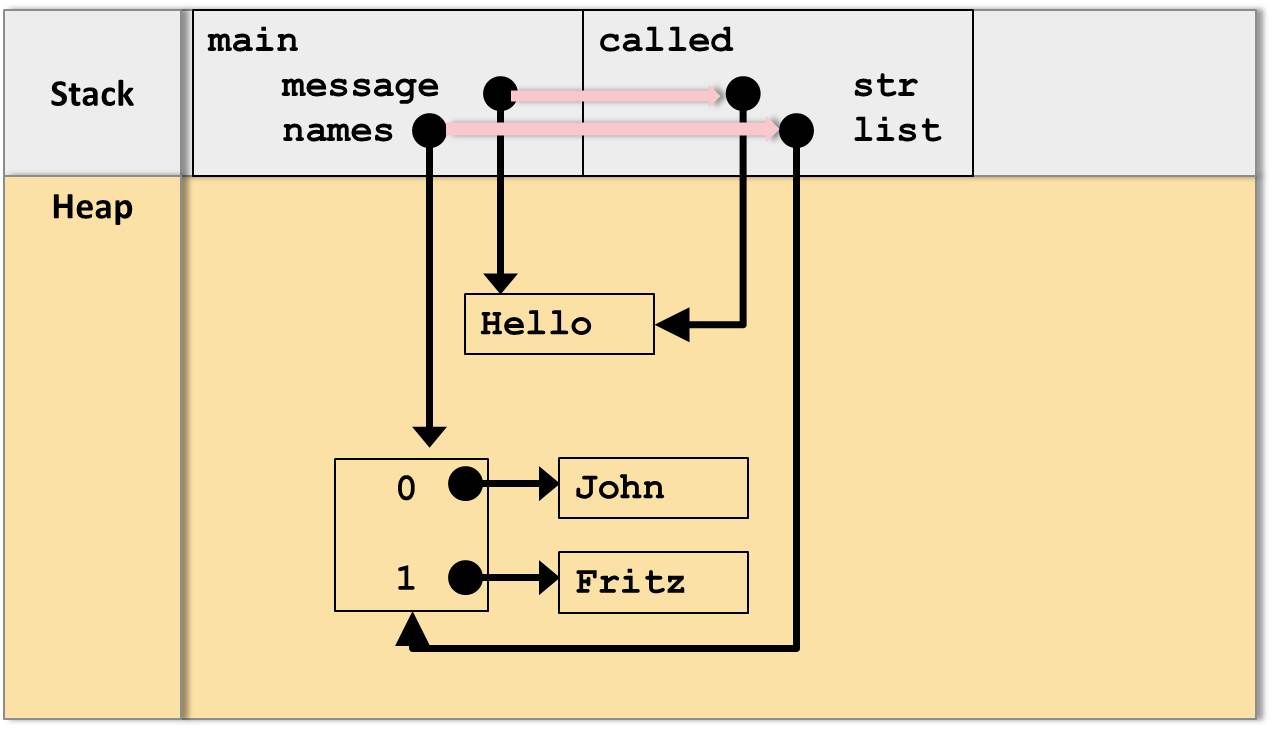
Im Endeffekt zeigen die Referenzen auf die selben Objekte im Heap.
Zuweisung von Werten
Was passiert aber nun, wenn in der aufgerufenen Methode den Parametern neue Werte zugewiesen werden? Hier ergibt sich ein feiner aber unglaublich wichtiger Unterschied: Belegen wir den Parameter str einfach mit einem neuen Wert, z.B. mit
str = "Goodbye";
so wird die Variable im Stack einfach mit einer Referenz auf das neue Objekt im Heap überschrieben:

Wichtig hier ist, dass in der aufrufenden main-Methode die Variable message davon völlig unbeeinflusst bleibt.
Was passiert aber, wenn wir die Referenz auf das Array benutzen, um beispielsweise den Wert des zweiten Elements mit Index 1 auf “Paul” zu setzen?
list[1] ="Paul";
Nun ergibt sich ein anderes Bild:
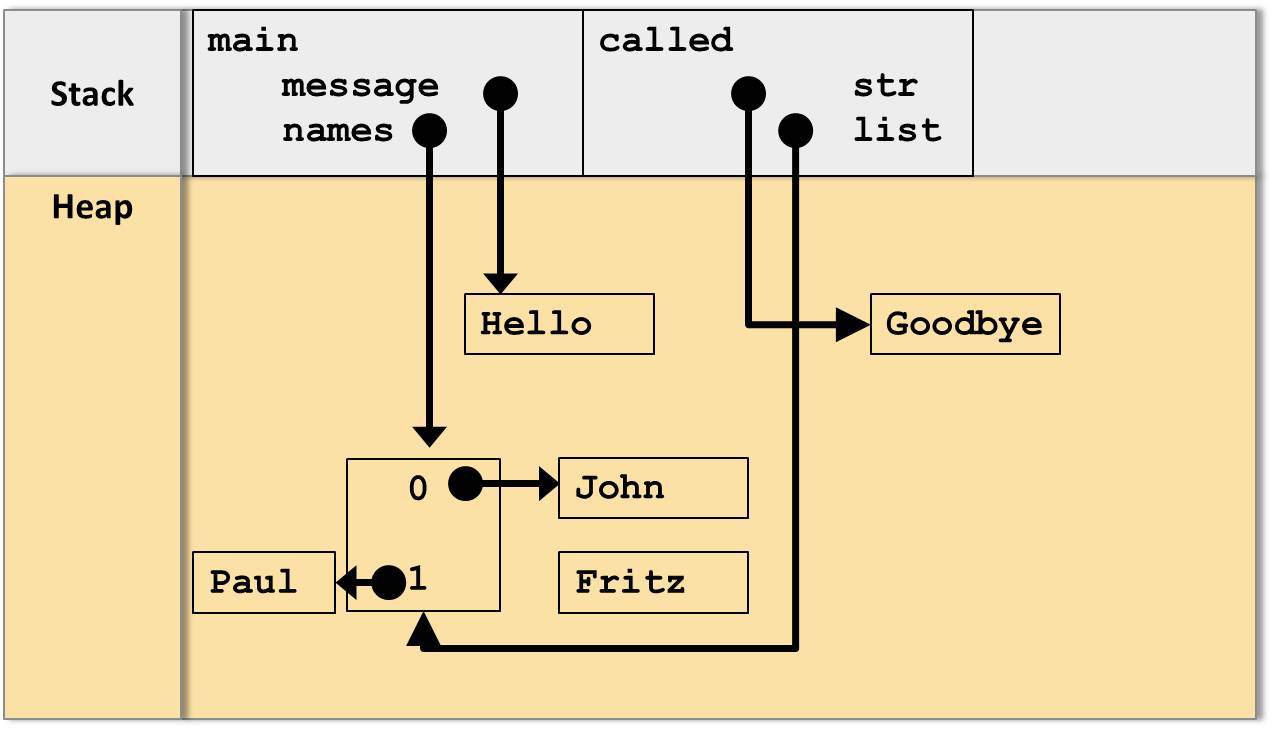
Hier ist klar ersichtlich, dass diese Änderung des Array-Objekts innerhalb der Methode called auch direkt Auswirkungen auf die aufrufende main-Methode hat: Nachdem die Methode called terminiert ist referenziert auch die Variable message auf das Array, dessen zweites Element nun auf “Paul” zeigt.
Also innerhalb von main
public static void main(String[] args){
String message = "Hello";
String[] names = {"John", "Fritz"};
called(message, names);
System.out.println(names[1]); //-> Paul
}Zusammenfassung und Ausblick
Durch die Betrachtung des Speichermodells der Java Virtual Machine wird die Arbeitsweise eines Objekt-orientierten Programms unter Verwendung von Referenzen klar und verständlich. Das komplette Beispiel liegt als fertiges Eclipse-Projekt vor und enthält zusätzlich Konsolen-Ausgaben, die den Ablauf des Programms demonstrieren. Selbstverständlich kann aber auch der Eclipse-Debugger benutzt werden, um die Ausführung nachzuvollziehen.
Allerdings sind sicherlich auch noch einige Punkte nicht fundiert behandelt worden:
- Das vorgestellte Speichermodell ist stark vereinfacht. Wie schaut es denn tatsächlich aus?
- Was passiert eigentlich mit dem armen Objekt “Fritz”, das nun komplett losgelöst im Heap vorhanden ist?
Diese beiden Punkte werden in einem folgenden Artikel, der den Garbage Collector der JVM als Thema hat, behandelt.