Übersicht
Messaging ist eine zentrale Technologie für die Kommunikation von Anwendungen untereinander. Dabei wird eine lose Kopplung über sogenannte Messages etabliert, die über einen Message-Provider verteilt werden. Wichtig hierbei ist eine garantierte und nachvollziehbare Übermittlung der Messages. Als Beispiel für Message-Provider dienen die etablierten Applikationsserver der JEE oder separate Produktlösungen wie Apache ActiveMQ/Artemis.
Im Rahmen einer Service-orientierten Architektur und einer Umsetzung beispielsweise mit Microservices steigt die Anzahl der zu übermittelnden Nachrichten sehr schnell an, damit die Services sich untereinander synchronisieren können. Auch hier ist ein möglichst flexibler Ansatz notwendig, um den Konfigurations- und Administrationsaufwand beherrschen zu können. Nachdem Microservices auf Grund der dezentralen Datenhaltung im Normalfall auf einer BASE-Architektur beruhen ist hier die Garantie des Message-Transports zwar immer noch gewünscht, allerdings liegt der Schwerpunkt hier mehr auf einer horizontal skalierbaren Lösung, die eine immense Menge von Messages verteilen kann. Hier hat sich insbesondere in der Java-Welt das auf Streaming basierende Apache Kafka etabliert.
Producer und Consumer
Um die Message-basierte Kommunikation zu veranschaulichen dient das folgende Bild aus der ActiveMQ-Dokumentation.
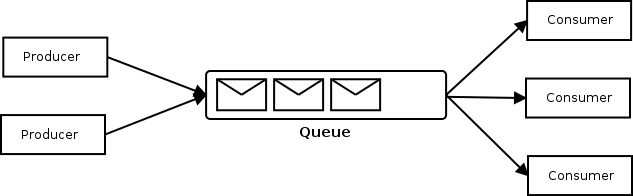
Diese Bild ist leicht zu verstehen: Producer senden Messages an eine Queue, die dann die eingetroffenen Nachrichten an die registrierten Consumers verteilt.
Im klassischen Messaging werden hierzu zwei unterschiedliche Strategien unterstützt:
- Beim Point-to-Point-Messaging wird die Nachricht an exakt einen Consumer übermittelt.
- Bei Publish-Subscribe werden alle Consumer die Message erhalten.
Bei Active MQ werden die Messages garantiert in einem Message Buffer auf Platte gespeichert und sind damit auch bei einem Neustart verfügbar. Weiterhin ist die Verweildauer der Message in der Queue prinzipiell beliebig lange möglich, so dass die Queue Lastspitzen ausgleichen kann bzw. bei ausgefallenen Consumern auch als Zwischenpuffer fungieren kann.
Streaming
Streaming funktioniert etwas anders: Hier werden die Nachrichten als (potenziell unendlich langer) Stream von Eingangsdaten aufgefasst, die von einem Stream Processor transformiert und damit verarbeitet werden. Dieses Konzept wird von Apache Kafka umgesetzt:
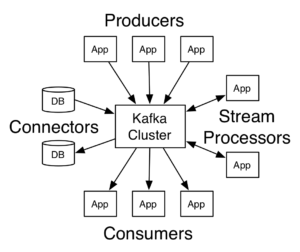
Wie in obigem Bild, das der Apache Kafka Webseite entnommen ist, erkennbar ist unterstützt Kafka zusätzlich noch das etablierte Producer/Consumer-Konzept, ist aber noch zusätzlich in der Lage, über Connectors Datenbank-Systeme anzubinden.
Durchsatz und Clusterbetrieb
ActiveMQ und Kafka sind beides Systeme, die auf hohen Nachrichtendurchsatz ausgerichtet sind. Wobei tausende von Nachrichten pro Sekunde für beide System noch nicht wirklich viel sind.
Trotzdem lohnt es sich, die beiden Systeme im Hinblick auf den Durchsatz und die Skalierbarkeit im Cluster-Betrieb zu vergleichen.
ActiveMQ verliert durch die Art der Nachrichtenpersistierung im Vergleich zu Apache Kafka deutlich. Dies liegt an der Art der Ablage der Messages, die bei ActiveMQ viel Wert auf eine sichere Ablage in einem, wahrscheinlich Datei-basierten, Message-Store legt. Der Aufbau eines ActiveMQ-Clusters verlangt eine relativ komplexe Systemarchitektur: Jeder einzelne Knoten benötigt eine Active/Passive-Instanz und die Skalierung des Systems verlangt eine intensive und aufwändige Kommunikation der Knoten untereinander.
Apache Kafka ist im Gegensatz hierzu recht einfach: Der Cluster skaliert horizontal und unterstützt ein automatisches Scale Up/Down. Die Ausfallsicherheit erreicht der Cluster durch eine interne Replikation der Nachrichten an mehrere Knoten.
Damit ist der Durchsatz und die Skalierbarkeit eines Kafka-Clusters wesentlich besser als ein äquivalentes ActiveMQ-System. Allerdings ist hierbei zu beachten, dass eine alleinige Betrachtung dieser beiden Features bei der Auswahl eines Produkts nicht ausreicht: Ein klassisches Messaging-System bietet mit Queues, Selectors, den verschiedenen Acknowledge-Modi, Redelivery und Dead Letter Queues viele interessante zusätzliche Dienste an, muss für deren Umsetzung dann aber auch mehr Aufwand betreiben.